

Nowadays, everyone is preaching that data is the new oil. But unlike oil, it’s not (just) the sheer output volume that matters here. What really counts is the efficient use of this data so as to draw the right conclusions in terms of the supply chain reliability.
The problem is not the data – it’s how to piece it together
Where this efficient use of data frequently fails is that the data is stored in separate silos that are difficult to merge. And yet: without data consolidation there can be no reliable results for risk assessment. The best analysis tools are worth little if they cannot be fed with all the relevant information available – tapping into all data sources, both internal and external.
If you take a closer look at data consolidation projects, you will see they often fail due to the differing data structures in the various data silos, making it very difficult to merge the data. What is more, companies are often unwilling to invest the effort and the cost involved in this type of project.
Risk minimization means risk anticipation
But leaving this information unused is not an option. After all, manufacturers increasingly expect their system suppliers to do everything that is technically possible to minimize supply chain risks. And this happens to include knowing all the risks that lie dormant in the supply chain so as to be able to get a handle on them.
In an increasingly complex world, it is virtually impossible to ensure a high level of supply chain reliability without anticipatory risk management – and no company can afford to do without it any more.
Comprehensive data lake enables 360° view and early counteraction
SupplyOn is able to tap into all data sources and merge them via standardized interfaces so as to provide a consolidated and therefore reliable analysis. For this purpose, the data from the operational order process such as article numbers, transport data and unloading points is enriched with data from external data sources. This includes information on extreme weather conditions and natural disasters, as well as details of traffic jams and strikes.
Even highly unstructured data from social media such as Facebook and Twitter can be integrated and incorporated in the analyses. The data lake created in this way is also enriched with data from sensors, such as those that continuously monitor environmental conditions like temperature and air humidity when sensitive components are being transported.
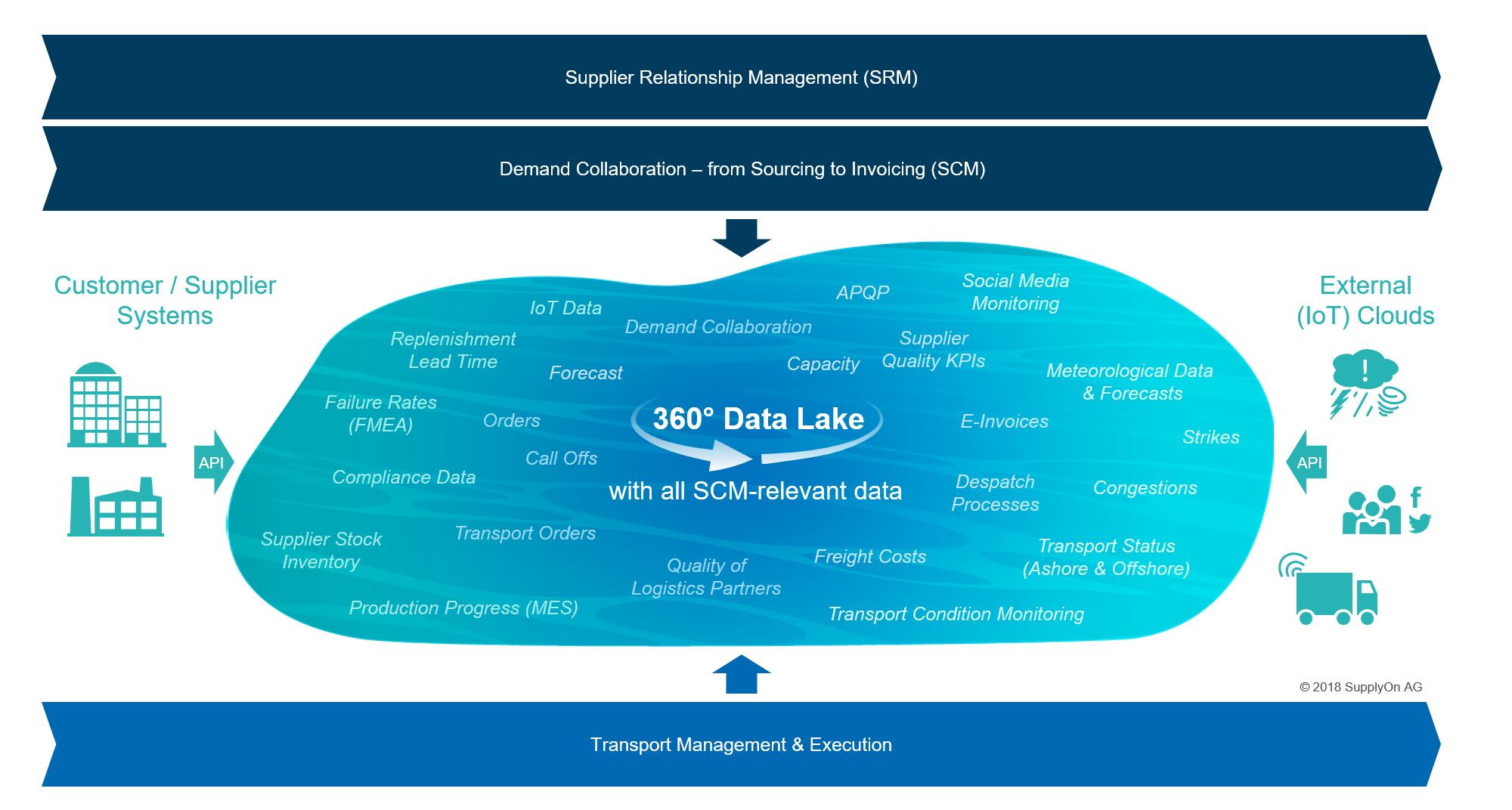
This data provides a comprehensive picture in the event of a problem: planning staff not only find out early on whether or not there is a problem with a particular transport, they can also trace precisely which purchased part and therefore which production stage is affected on their side. They can now use this information to specifically intervene in the process – regardless of the importance of the part in question as far as internal production or the customer are concerned. This enables the work involved and therefore the cost of eliminating the problem to be precisely controlled.
Risk data can also be internally processed
In addition to clearly indicating risks in the supply chain in the SupplyOn Analytics solution, customers can also process this data in their own systems. From the technical point of view, there are several ways to access and provide this data: SupplyOn can provide the data as database excerpts (dump) or as structured data sets on the customer’s own systems such as ERP systems and internal data lakes. Another data provision option here is access via an API interface.
The advantage: risk minimization at all levels
- The biggest advantage of successful data consolidation is substantially minimizing supply chain risks – involving very little in terms of personnel and cost.
- Risks can be precisely isolated and attributed to clearly defined part numbers and transports – enabling targeted intervention.
- Measures and their effects can also be displayed and incorporated in the analysis.
- All analyses can be provided simply and made accessible to third parties such as customers.


